|
SD-MVSum: a method for Script-driven Multimodal Video Summarization
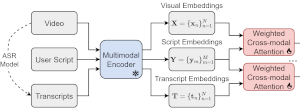
SD-MVSum builds on our earlier SD-VSum method for script-driven video summarization, which considered just the visual content of the video. SD-MVSum takes into account, in addition to the visual modality, the relevance of the user-provided script with the spoken content (i.e., audio transcript) of the video. The dependence between each considered pair of data modalities, i.e., script-video and script-transcript, is modeled using a new weighted cross-modal attention mechanism that explicitly exploits the semantic similarity between the paired modalities. |
|
|
SD-VSum: a method for Script-driven Video Summarization
We introduce the new task of script-driven video summarization, which aims to produce a summary of the full-length video by selecting the parts that are most relevant to a user-provided script outlining the visual content of the desired summary. For this task, we propose a new network architecture, SD-VSum, that employs a cross-modal attention mechanism for aligning and fusing information from the visual and text (script) modalities. |

|
|
P-TAME: Explain Any Image Classifier with Trained Perturbations.
P-TAME (Perturbation-based Trainable Attention Mechanism for Explanations) is a model-agnostic method for explaining DNN-based image classifiers. It uses an auxiliary image classifier to extract features from the input image, bypassing the need to modify the explanation method so that it matches the specific architecture of the classifier being explained. Unlike traditional perturbation-based methods, P-TAME generates high-resolution explanations efficiently in a single forward pass during inference. |

|
|
TSalV360: A Method for Text-driven Saliency Detection in 360-Degrees Videos.
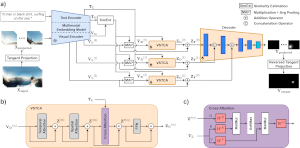
We introduce the TSalV360 method. This extends a SOTA visual-based approach for 360-degrees video saliency detection, to take into account a user-provided text description of the desired objects and/or events. TSalV360 leverages a SOTA vision-language model for data representation and integrates a similarity estimation module and a viewport spatio-temporal cross-attention mechanism, to discover dependencies between the different data modalities. The developed method can successfully perform customized text-driven saliency detection in 360-degrees videos. |
|
|
Generating Plausible Textual Explanations for Video Summarization.
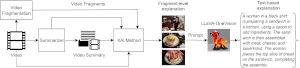
This software can be used to generate plausible textual explanations for the outcomes of a video summarization model. More specifically, our framework produces: a) visual explanations including the video fragments that influenced the most the decisions of the summarizer, using model-specific (attention-based) and model-agnostic (LIME-based) explanation methods, and b) plausible textual explanations by integrating a state-of-the-art Large Multimodal Model (LLaVA-OneVision) and prompting it to produce natural language descriptions of the produced visual explanations. |
|
|
VidCtx: Context-aware Video Question Answering with Image Models.
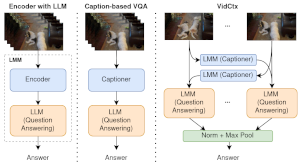
We introduce VidCtx, a novel training-free VideoQA framework which integrates both visual information from input frames and textual descriptions of others frames that give the appropriate context. More specifically, in VidCtx a pre-trained Large Multimodal Model (LMM) is prompted to extract at regular intervals, question-aware textual descriptions (captions) of video frames. Those will be used as context when the same LMM will be prompted to answer the question at hand given as input a) a certain frame, b) the question and c) the context/caption of an appropriate frame. We release our evaluation and inference code; VidCtx is a zero-shot approach and requires no additional training. |
|
|
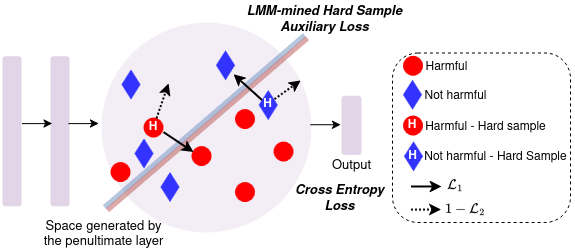
Multimodal hateful meme detection exploiting LMM-generated knowledge.
We provide code and trained models for our LMM-CLIP and LMM-LongCLIP methods for hateful meme detection. These leverage an LMM in a two-fold manner: for extracting knowledge oriented to the hateful meme detection task, in order to build strong meme representations; and, for introducing a hard mining approach based on LMM-encoded knowledge to the training of the hateful meme detector. |
|
|
T-TAME: Transformer-compatible Trainable Attention Mechanism for Explanations.
T-TAME is an extension of our earlier TAME method; it is a post-hoc explanation method for both DCNN-based and Transformer-based image classifiers. T-TAME can be easily applied to any such classifier using a streamlined training approach; and, after training, explanation maps can be efficiently computed in a single forward pass. We have tested T-TAME on VGG-16, ResNet-50, and ViT-B-16 classifiers trained on ImageNet. |

|
|
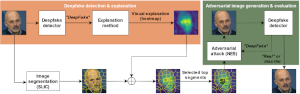
Explainable AI for Deepfake Detection.
We provide code, models and data for our method on improving the perturbation-based explanation of deepfake detectors through the use of adversarially-generated samples. We also provide materials for evaluating the performance of five explanation approaches from the literature (GradCAM++, RISE, SHAP, LIME, SOBOL), on explaining the output of a state-of-the-art model (based on Efficient-Net) for deepfake detection. |
|
|
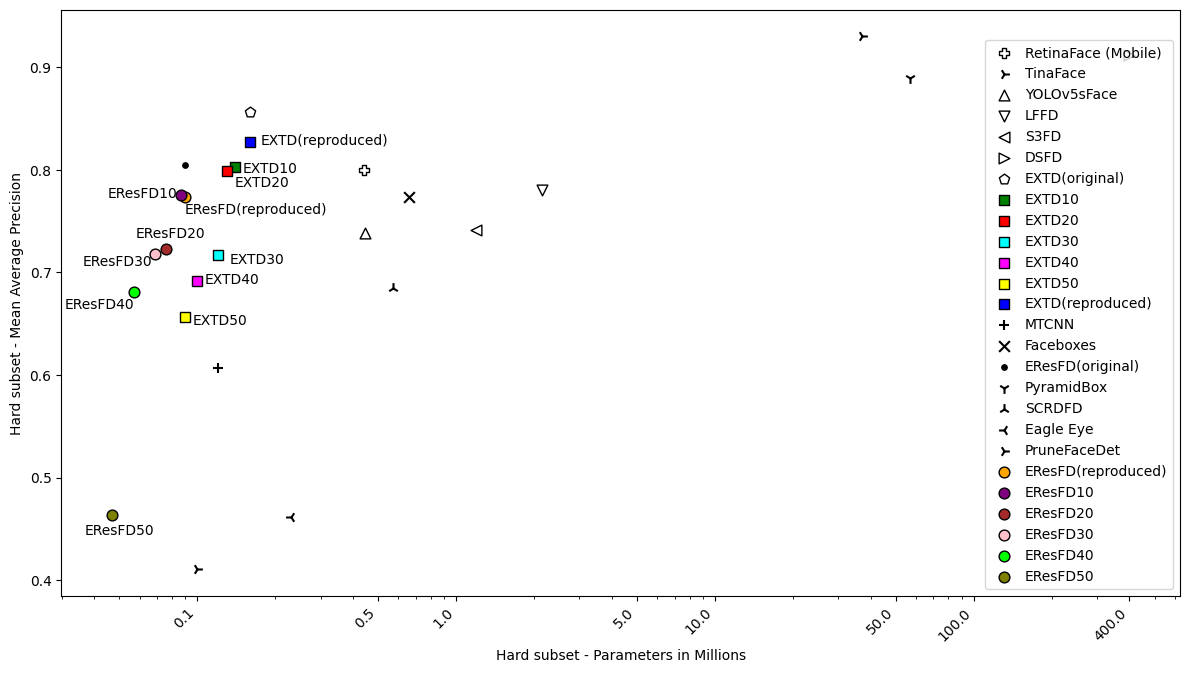
Pruned Lightweight Face Detectors.
We investigate the application of filter pruning on two already small and compact face detectors, EXTD (Extremely Tiny Face Detector) and EResFD (Efficient ResNet Face Detector). We combine Bayesian optimization, for tuning the pruning rate of different parts of the detector's architecture, with a Filter Pruning via Geometric Median (FPGM) algorithm. We show that in this way we can further reduce the model size of already lightweight face detectors, with limited accuracy loss, or even with a small accuracy gain for low pruning rates. |
|
|
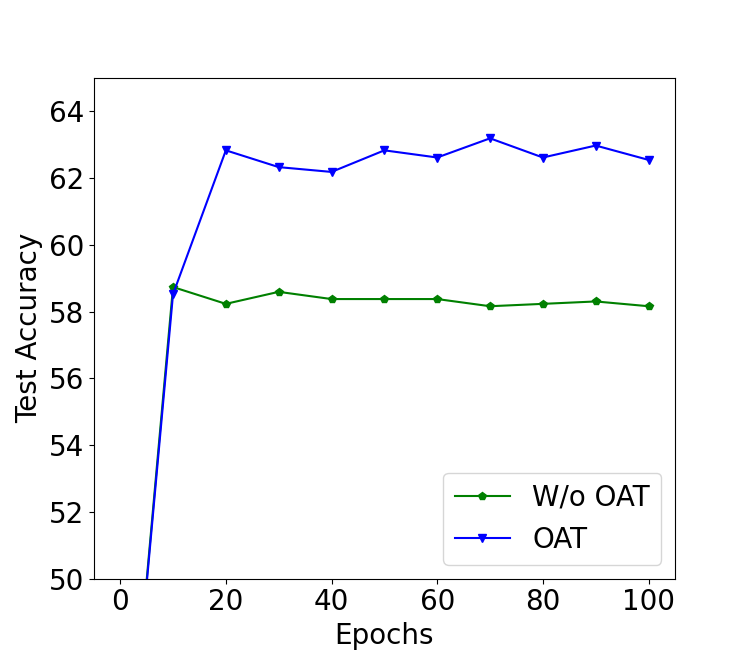
OAT: Online Anchor-based Training.
We improve deep learning models for image classification by proposing an Online Anchor-based Training methodology (OAT). OAT, guided by the insights provided in anchor-based object detection, instead of learning directly the class labels proposes to train a model to learn percentage changes of the class labels with respect to defined anchors. We define as anchors the batch centers at the output of the model. During inference, the predictions are converted back to the original class label space. |
|
|
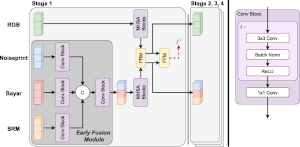
Multi-Modal Fusion for Image Manipulation Detection and Localization.
We showcase that different image manipulation filters excel at unveiling different types of manipulations and provide complementary forensic traces. To take advantage of this, we propose two ways for merging the outputs of such filters to perform more accurate image manipulation localization and detection. |
|
|
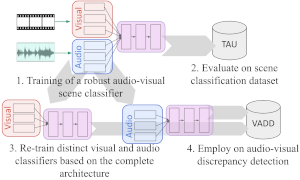
Detecting Visual-Audio Discrepancies in Video.
We provide scripts and trained models for detecting discrepancies in video: uni-modal classifiers that can be applied separately to the audio / visual modality to detect scene-class inconsistencies between them, and a joint audio-visual scene classification model. We also provide a benchmark dataset simulating such audio-visual inconsistencies. |
|
|
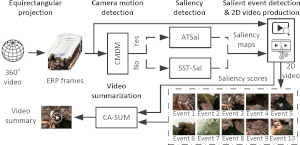
Spatio-Temporal Summarization of 360-degrees Videos.
We combine a camera motion detection method, two saliecy detection methods for generating frame-level saliency maps, a salient event detection approach for extracting traditional 2D+time video volumes from the 360-degrees video, and an adapted state-of-the-art video summarization method, to transform 360-degrees videos to video summaries that are suitable for traditional video distribution channels. |
|
|
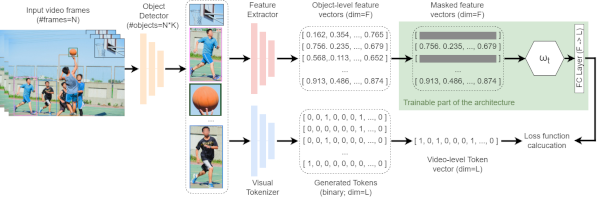
Masked-ViGAT: Masked Feature Modelling for Video Event Recognition.
We introduce Masked Feature Modelling (MFM) for the unsupervised pretraining of a Graph Attention Network (GAT) block. MFM utilizes a pretrained Visual Tokenizer to reconstruct masked features of objects within a video, leveraging the MiniKinetics dataset. We then incorporate the pre-trained GAT block into a state-of-the-art bottom-up supervised video-event recognition architecture, ViGAT, to improve the model's accuracy in a smaller target dataset. |
|
|
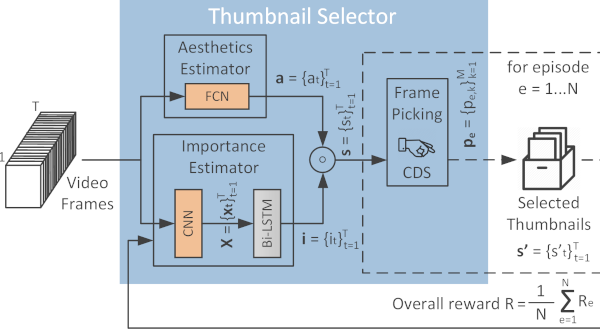
RL-DiVTS: Selecting diverse, representative and aesthetically-pleasing video thumbnails.
RL-DiVTS is a new reinforcement-based method for video thumbnail selection, that relies on estimates of the frames' aesthetic quality, representativeness and visual diversity, made with the help of tailored reward functions. It integrates a novel diversity-aware Frame Picking mechanism that performs a sequential frame selection and applies a reweighting process to demote frames that are visually-similar to the already selected ones. |
|
|
TAME: Trainable Attention Mechanism for Explanations.
TAME is a method for post-hoc explanation of DCNN-based image classifiers. TAME learns to generate explanation maps by introducing a multi-branch hierarchical attention mechanism. This mechanism is trained end-to-end along with the original (frozen) DCNN, to derive class activation maps (CAMs) using the feature maps (FMs) coming from multiple layers of the original DCNN. After training, explanation maps can be computed in a single forward pass. |

|
|
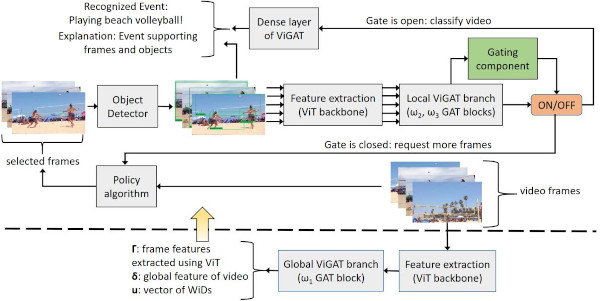
Gated-ViGAT: Efficient Bottom-Up Event Recognition.
Gated-ViGAT combines bottom-up (object) information, a new frame sampling policy and a gating mechanism for video event recognition. The frame sampling policy uses weighted in-degrees (WiDs), derived from the adjacency matrices of graph attention networks (GATs), and a dissimilarity measure to select the most salient and diverse frames. The gating mechanism fetches the selected frames and commits early exiting when an adequately confident decision is achieved. |
|
|
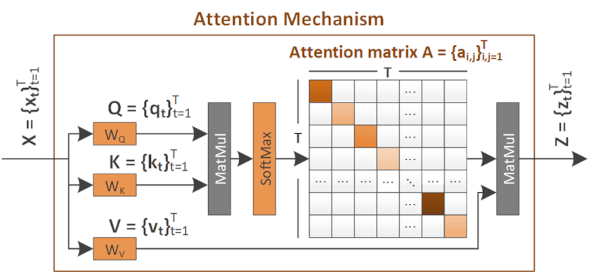
Explaining video summarization based on the focus of attention.
The problem we address is the creation of an explanation mask, which indicates the parts of the video that influenced the most the estimates of a video summarization network about the frames' importance. We examine various attention-based signals and we evaluate their performance in combination with different replacement functions, and utilizing measures that quantify the capability of explanations to spot the most and least influential parts of a video. |
|
|
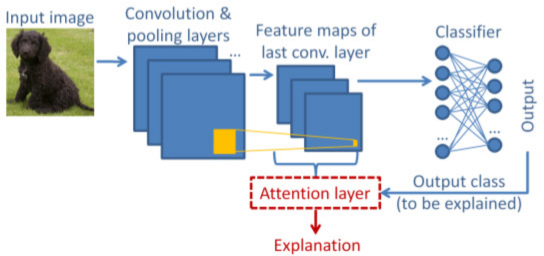
L-CAM: Learning Visual Explanations for DCNN-Based Image Classifiers.
We provide code and associated materials for two learning-based eXplainable AI (XAI) methods, L-CAM-Fm and L-CAM-Img, for DCNN image classifiers. Our methods receive as input an image and a class label and produce as output the image regions that the DCNN has focused on in order to infer this class. Both methods use an attention mechanism (AM), trained end-to-end along with the original (frozen) DCNN, to derive class activation maps (CAMs) from the last convolutional layer's feature maps (FMs). |
|
|
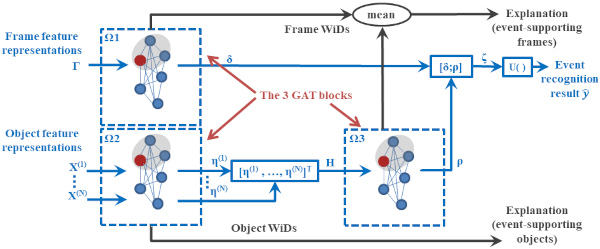
ViGAT: Video Event Recognition and Explanation.
This software can be used for training our deep learning architecture called ViGAT, which utilizes an object detector together with a Vision Transformer (ViT) backbone network to derive object and frame features, and a head network to process these features for the task of event recognition and explanation in video. Our ViGAT method makes unique contributions in the areas of bottom-up event recognition and explainable AI for video understanding. |
|
|
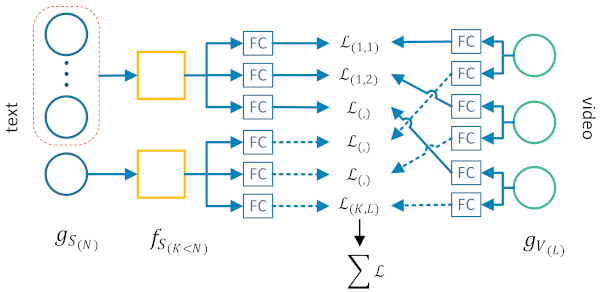
T-times-V for text-based video retrieval.
We provide the implementation of our T-times-V method for free-text-based video retrieval. Our method learns how to combine multiple diverse textual and visual features towards generating multiple joint feature spaces, which encode text-video pairs into comparable representations. It also introduces an additional softmax operation at the retrieval stage, for revising the query-video similarities inferred by the trained network. |
|
|
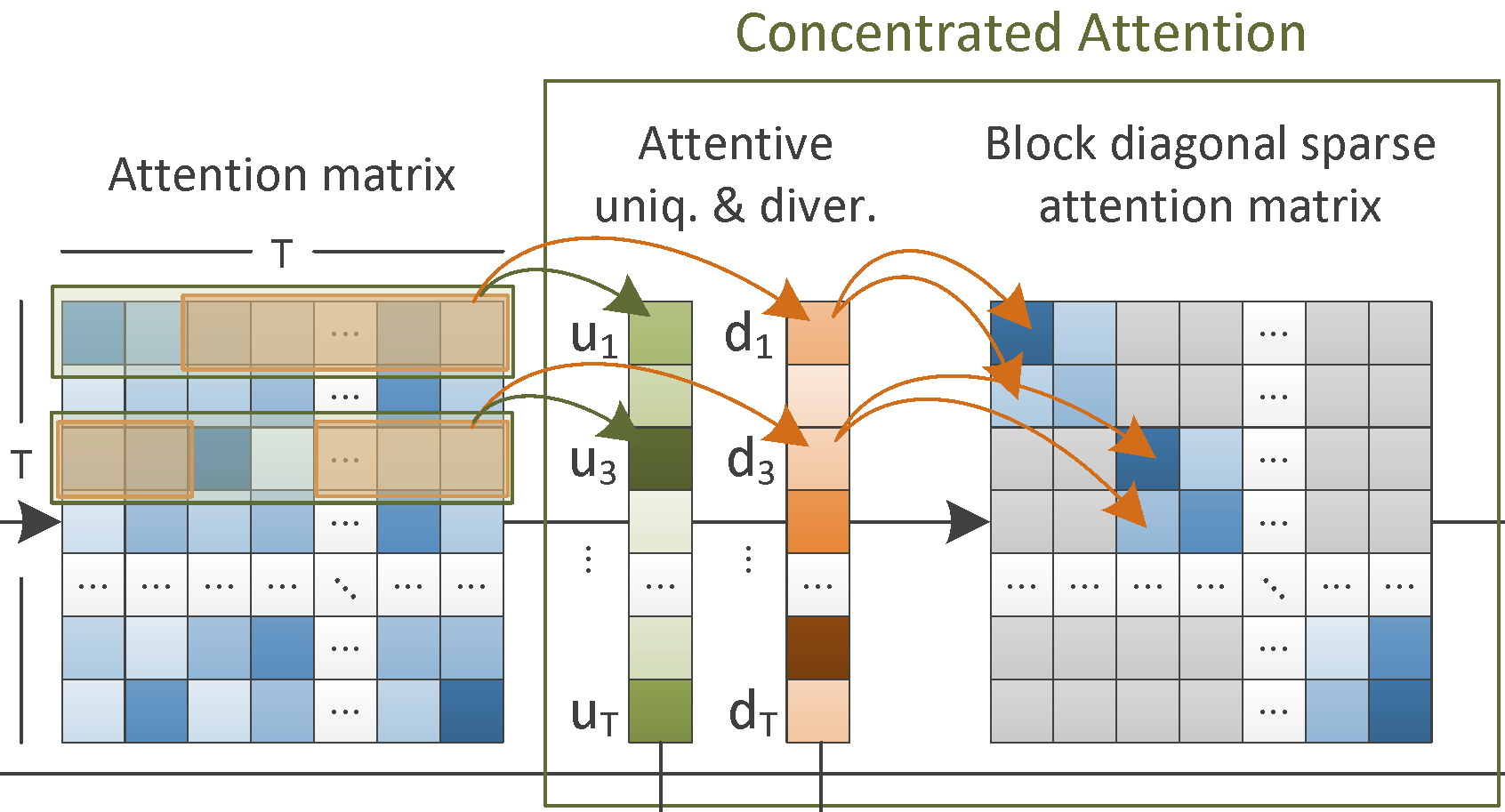
CA-SUM for Unsupervised Video Summarization
This software can be used for training a deep learning architecture, which estimates frames' importance by integrating a concentrated attention mechanism and utilizing information about the frames' uniqueness and diversity. Training is performed in an unsupervised manner. After being on a collection of videos, the CA-SUM model is capable of producing summaries for unseen videos, according to a user-specified time-budget about the summary duration. |
|
|
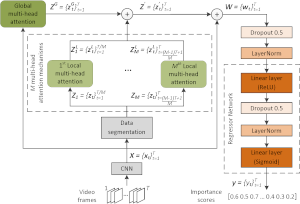
PGL-SUM for Supervised Video Summarization
This software can be used for training a deep learning architecture which estimates the frames' importance after modeling their dependencies with the help of global and local multi-head attention mechanisms that integrate a positional encoding component. Training is performed in a supervised manner (using human-generated video summaries). After being trained, the PGL-SUM model can produce representative summaries for unseen videos, according to a user-specified time-budget about the summary duration. |
|
|
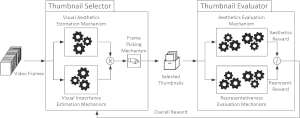
Video Thumbnail Selector: Combining Adversarial and Reinforcement Learning
This software can be used for training a deep learning architecture for video thumbnail selection, taking under consideration the representativeness and the aesthetic quality of the video frames. Training is fully-unsupervised, based on a combination of adversarial and reinforcement learning. After being trained on a collection of videos, the Video Thumbnail Selector is capable of selecting a set of representative video thumbnails for unseen videos. |
|
|
SmartVidCrop: A Fast Cropping Method for Video Retargeting
This is an implementation of our fast video cropping method, which allows adapting an input video to a different aspect ratio while staying focused on the original video's main subject. Our method utilizes visual saliency to find the regions of attention in each frame, and employs a filtering-through-clustering technique as well as temporal filters to select the main region of focus and produce a smooth sequence of cropped frames. |

|
|
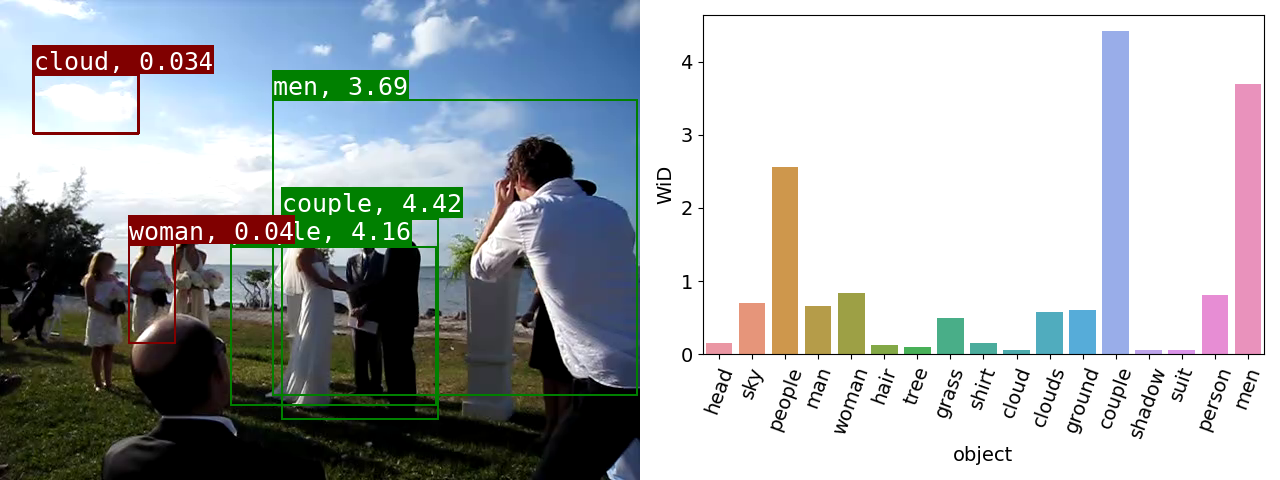
ObjectGraphs: Video Events Recognition and Explanation
This is an implementation of ObjectGraphs, our novel bottom-up video event recognition and explanation approach. It combines object detection, a graph convolutional network (GCN) and a long short-term memory (LSTM) network for performing video event recognition as well as for identifying the objects that contributed the most to the event recognition decisions, thus providing explanations for the latter. |
|
|
AC-SUM-GAN for Unsupervised Video Summarization
This is an implementation of our latest video summarization method, presented in our paper "AC-SUM-GAN: Connecting Actor-Critic and Generative Adversarial Networks for Unsupervised Video Summarization", IEEE Trans. on Circuits and Systems for Video Technology (IEEE TCSVT), 2020 (early access). This is, to date, our most complete and best-performing method for video summarization. |
|
|
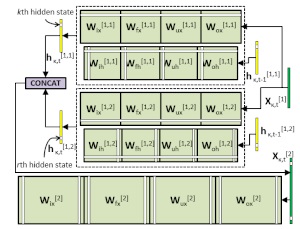
Structured Pruning of LSTMs
We provide the code for our paper "Structured Pruning of LSTMs via Eigenanalysis and Geometric Median for Mobile Multimedia and Deep Learning Applications", Proc. 22nd IEEE Int. Symposium on Multimedia (ISM), Dec. 2020. This code can be used for generating more compact LSTMs, which is very useful for mobile multimedia applications and deep learning applications in other resource-constrained environments. |
|
|
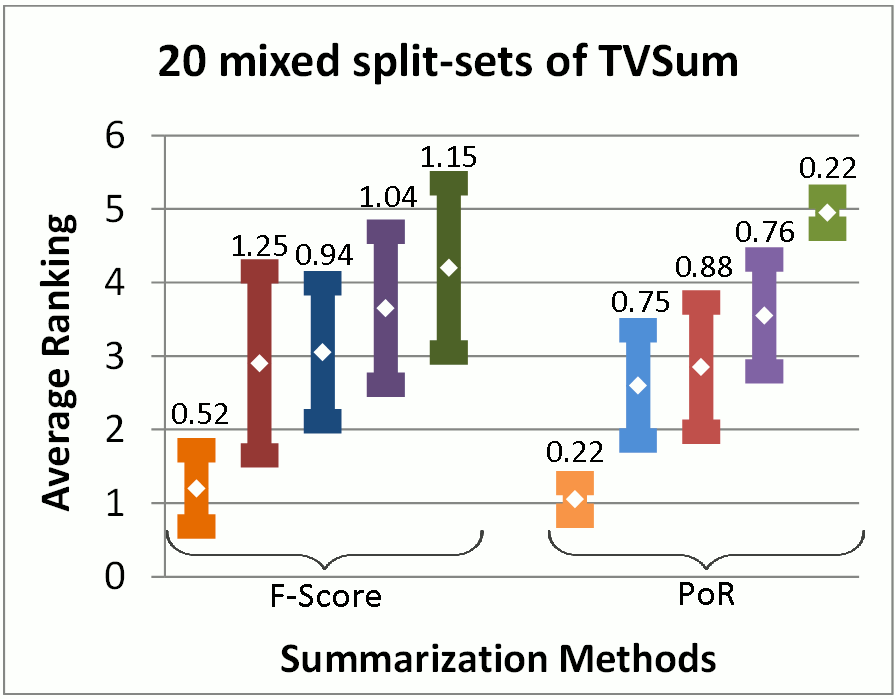
Video Summarization Evaluation: Performance over Random
We provide an implementation of our video summarization evaluation method presented in our publication "Performance over Random: A Robust Evaluation Protocol for Video Summarization Methods", Proc. 28th ACM Int. Conf. on Multimedia (ACM MM '20). This software can be used for evaluating automatically-generated video summaries using the Performance over Random (PoR) evaluation protocol. |
|
|
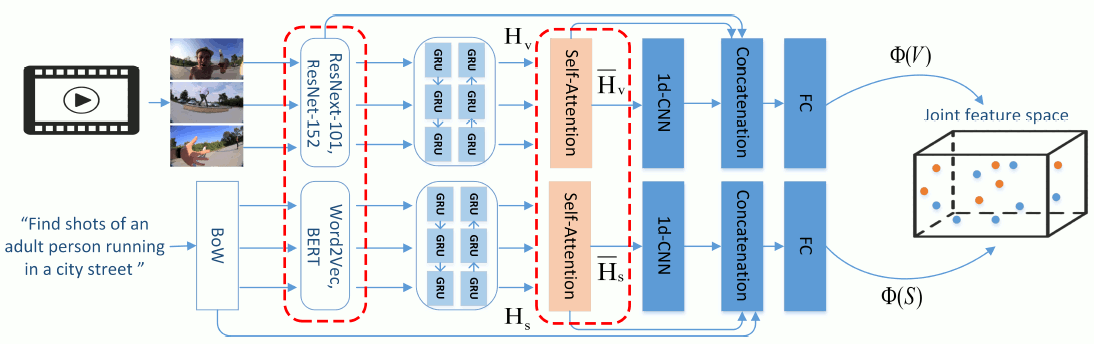
Dual Encoding Attention Network for ad-hoc Video Search
We provide an implementation of our extended dual encoding network for ad-hoc video search, presented at ACM ICMR 2020. This network makes use of more than one encodings of the visual and textual content, as well as two different attention mechanisms. |
|
|
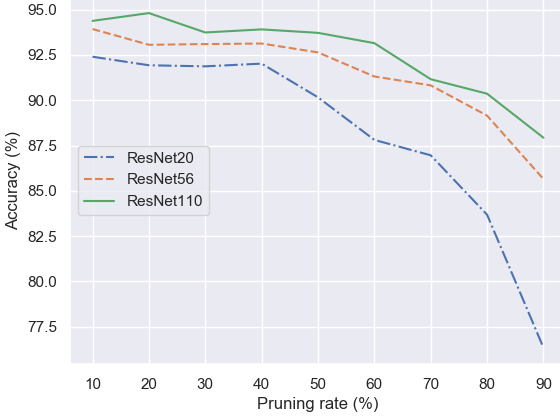
Fractional Step Discriminant Pruning for DCNNs
This is an implementation of our filter pruning framework for DCNNs, presented at the IEEE ICME 2020 Mobile Multimedia Computing Workshop. This framework compresses noisy or less discriminant filters in small fractional steps, utilizing a class-separability criterion and an asymptotic schedule for the pruning rate and scaling factor, so that the selected filters' weights are gradually reduced to zero. |
|
|
SM-MrHiSum and SM-VideoXum datasets for Script-driven Multimodal Video Summarization
We present two datasets that are suitable for script-driven multimodal video summarization, extending the original MrHiSum and VideoXum datasets. SM-MrHiSum contains 29,917 videos, where each video is associated with: a) a ground-truth summary, b) a textual description of this summary (the so-called script), and c) a set of time-stamped audio transcripts. SM-VideoXum contains 11,908 videos, where each video is associated with: a) 10 ground-truth summaries, b) 10 textual descriptions of its summaries (one description per summary), and c) a set of time-stamped audio transcripts. |

|
|
Sens-VisualNews dataset
The detection of sensational content in media items can be a critical filtering mechanism for identifying check-worthy content and flagging potential disinformation, since such content triggers physiological arousal that often bypasses critical evaluation and accelerates viral sharing. To support research on the task of sensational image detection, we create a new benchmark dataset (called Sens-VisualNews) that contains 9,576 images from news items, annotated based on the (in-)existence of various sensational concepts and events in their visual content. |
|
|
S-VideoXum: a dataset for Script-driven Video Summarization
We introduce S-VideoXum, a dataset derived from the existing VideoXum summarization dataset. To make VideoXum suitable for training and evaluation of script-driven video summarization methods, we extended it by producing natural language descriptions of the 10 ground-truth summaries that are available per video. These serve as the scripts that can drive the summarization process. S-VideoXum is made of 119,080 scripts corresponding to 11,908 videos (split in 6,782 videos for training, 3,419 for validation and 1,707 for testing). |
|
|
TSV360 dataset for text-driven saliency detection in 360-degrees videos
TSV360 is a dataset for training and objective evaluation of text-driven 360-degrees video saliency detection methods. It contains textual descriptions and the associated ground-truth saliency maps, for 160 videos (up to 60 seconds long) sourced from the VR-EyeTracking and Sports-360 benchmarking datasets. These datasets cover a wide and diverse range of 360-degrees visual content, including indoor and outdoor scenes, sports events, and short films. |

|
|
360-VSumm dataset
We introduce a new dataset for 360-degree video summarization: the transformation of 360-degree video content to concise 2D-video summaries that can be consumed via traditional devices, such as TV sets and smartphones. The dataset includes ground-truth human-generated summaries. We also present an interactive tool that was developed to facilitate the data annotation process and can assist other annotation activities that rely on video fragment selection. |
|
|
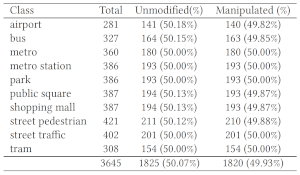
VADD dataset
We introduce the Visual-Audio Discrepancy Detection (VADD) dataset and experimental protocol, curated to facilitate research in detecting discrepancies between visual and audio streams in videos. The dataset includes a subset of videos in which the visual content portrays one class (e.g., an outdoor scenery), while the accompanying audio track is sourced from a different class (e.g., the sound of an indoor environment). |
|
|
RetargetVid: a video retargeting dataset
We provide a benchmark dataset for video cropping: annotations (i.e., ground-truth croppings in the form of bounding boxes), for two target aspect ratios (1:3 and 3:1). These annotations were generated by 6 human subjects for each of 200 videos. The actual videos belong to the already-publicly-available DHF1k dataset. |
|
|
Interactive video summarizer
This web demo lets you submit videos in various formats and generate summaries for use in various social media channels. It uses our homegrown deep learning techniques for automated video summarization and aspect ratio transformation, combining them with an interactive user interface that allows the user to have editorial control over the final video summary. Try the demo with your choice of videos.
|

|
|
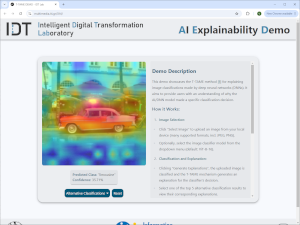
AI Explainability demo
This web demo showcases the T-TAME method for explaining DNN-based image classifiers. You can upload an image from your local device and select the image classifier model to be used from a dropdown menu (supported: ViT-B-16, ResNet50, VGG16); then, view the classification decisions and the corresponding explanations (heatmaps) for the top-5 detected image classes. Try the demo with your own images.
|
|
|
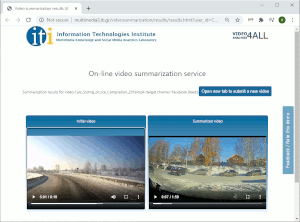
On-line video summarization
This web service lets you submit videos in various formats, and uses a variation of our SoA deep-learning-based summarization methods (relying on Generative Adversarial Networks) to automatically generate video summaries that are customized for use in various social media channels. Watch a 2-minute tutorial video for this service, and make the most out of your content by generating your own video summaries.
|
|
|
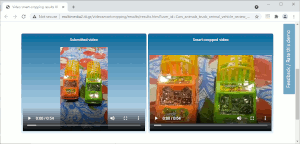
On-line video smart-cropping
A web service similar to the summarization one, however adapting only the aspect ratio of the input video without changing the video's duration. The input video can be of any aspect ratio, and various popular target aspect ratios are supported. Try the service with your own videos.
|
|
|
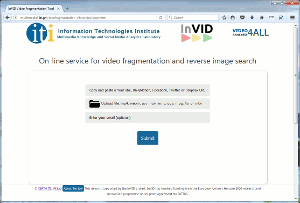
On-line video fragmentation and reverse image search
This web service lets you extract a set of representative keyframes from a video, and use these keyframes to perform fine-grained reverse video search with the help of the Google Image Search functionality, in order to find out if this video has appeared before on the Web. To submit a video for analysis the user can either provide its URL (several online video sources are supported), or upload a local copy of it from his/her PC. Try the service yourself. |
|
|
On-line video analysis and annotation services
We have developed several on-line services for the analysis and annotation of audio-visual material. Our latest interactive web service (v5.0) lets you upload videos in various formats, and performs shot and scene segmentation as well as visual concept detection with the YouTube-8M concepts. The processing is fast (several times faster than real-time video processing). The results are displayed with the help of an interactive user interface, offering various fragment-level navigation, playback and search functionalities. Watch a tutorial video for the service, and try the latest version (v5.0) of the service, or the previous one (v4.0) (using a different concepts set) with your own videos. |

|
|
MLLM Frame Subset Ensembling for Audio-Visual Video QA. Presentation available in Slideshare. Delivered at TREC 2025 Workshop, in Dec. 2025. |
|
MLLM-based Reranking for Ad-hoc Video Search. Presentation available in Slideshare. Delivered at TREC 2025 Workshop, in Dec. 2025. |
|
SD-VSum: A Method and Dataset for Script-Driven Video Summarization. Presentation available in Slideshare. Delivered at ACM Multimedia (ACM MM 2025), in Oct. 2025. |
|
TSalV360: A Method and Dataset for Text-driven Saliency Detection in 360-Degrees Videos. Presentation available in Slideshare. Delivered at the IEEE Int. Conf. on Content-Based Multimedia Indexing (CBMI 2025), in Oct. 2025. |
|
An Experimental Study on Generating Plausible Textual Explanations for Video Summarization. Presentation available in Slideshare. Delivered at the IEEE Int. Conf. on Content-Based Multimedia Indexing (CBMI 2025), in Oct. 2025. |
|
Cross-modal Image Recommendation for News Articles by Multimodal Foundation Models-based Retrieval-Reranking. Presentation available in Slideshare. Delivered at the 2025 Multimedia Evaluation Workshop (MediaEval'25), in Oct. 2025. |
|
Combatting video-borne disinformation and increasing trust in AI methods. Presentation available in Slideshare. Delivered at the AIDA Symposium and Summer School on "AI/ML Cutting Edge Trends" (AIDA AICET2025), in July 2025. |
|
An LLM Framework for Long-form Video Retrieval and Audio-Visual Question Answering Using Qwen2/2.5. Presentation available in Slideshare. Delivered at the Int. Workshop on Interactive Video Search and Exploration (IViSE) of CVPR 2025, in June 2025. |
|
Improving the Perturbation-Based Explanation of Deepfake Detectors Through the Use of Adversarially-Generated Samples. Presentation available in Slideshare. Delivered at the AI4MFDD Workshop of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2025), in Feb. 2025. |
|
B-FPGM: Lightweight Face Detection via Bayesian-Optimized Soft FPGM Pruning. Presentation available in Slideshare. Delivered at the RWS Workshop of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2025), in Feb. 2025. |
|
AI-powered Keyframe Selection and Enhancement. Webinar available in YouTube. Delivered as part of the webinar series organized by EBU under the auspices of the vera.ai project, in Feb. 2025. |
|
LMM-Regularized CLIP Embeddings for Image Classification. Presentation available in Slideshare. Delivered at the 26th Int. Symp. on Multimedia (IEEE ISM 2024), in Dec. 2024. |
|
Disturbing Image Detection Using LMM-Elicited Emotion Embeddings. Presentation available in Slideshare. Delivered at the LVLM Workshop of the 2024 IEEE Int. Conf. on Image Processing (ICIP 2024), in Oct. 2024. |
|
Detecting visual-media-borne disinformation: a summary of latest advances at the IDT Lab of CERTH-ITI. Presentation available in Slideshare. Delivered at the Thessaloniki-TechLab event, in June 2024. |
|
Exploiting LMM-based knowledge for image classification tasks. Presentation available in Slideshare. Delivered at the 25th Int. Conf. on Engineering Applications of Neural Networks (EANN/EAAAI 2024), in June 2024. |
|
A Human-Annotated Video Dataset for Training and Evaluation of 360-Degree Video Summarization Methods. Presentation available in Slideshare. Delivered at the 1st Int. Workshop on Video for Immersive Experiences (Video4IMX-2024) of ACM IMX 2024, in June 2024. |
|
Visual and audio scene classification for detecting discrepancies in video: a baseline method and experimental protocol. Presentation available in Slideshare. Delivered at the ACM Int. Workshop on Multimedia AI against Disinformation (MAD’24) of the ACM Int. Conf. on Multimedia Retrieval (ICMR’24), in June 2024. |
|
Towards Quantitative Evaluation of Explainable AI Methods for Deepfake Detection. Presentation available in Slideshare. Delivered at the ACM Int. Workshop on Multimedia AI against Disinformation (MAD’24) of the ACM Int. Conf. on Multimedia Retrieval (ICMR’24), in June 2024. |
|
Exploring Multi-Modal Fusion for Image Manipulation Detection and Localization. Presentation available in Slideshare. Delivered at the 30th Int. Conf. on MultiMedia Modeling (MMM 2024), in Jan.-Feb. 2024. |
|
An Integrated System for Spatio-Temporal Summarization of 360-degrees Videos. Presentation available in Slideshare. Delivered at the 30th Int. Conf. on MultiMedia Modeling (MMM 2024), in Jan.-Feb. 2024. |
|
Masked Feature Modelling for the unsupervised pre-training of a Graph Attention Network block for bottom-up video event recognition. Presentation available in Slideshare. Delivered at the 25th IEEE Int. Symp. on Multimedia (ISM 2023), in Dec. 2023. |
|
The QuaLiSID system and related video analysis technologies for supporting individuals with intellectual disabilities. Presentation delivered at the Kleefstra Syndrome Scientific Conference 2023, Ljubljana, Slovenia, in June 2023. |
|
TAME: Attention Mechanism Based Feature Fusion for Generating Explanation Maps of Convolutional Neural Networks. Presentation available in Slideshare. Delivered at the IEEE Int. Symposium on Multimedia (ISM), in Dec. 2022. |
|
Gated-ViGAT: Efficient bottom-up event recognition and explanation using a new frame selection policy and gating mechanism. Presentation available in Slideshare. Delivered at the IEEE Int. Symposium on Multimedia (ISM), in Dec. 2022. |
|
Explaining video summarization based on the focus of attention. Presentation available in Slideshare. Delivered at the IEEE Int. Symposium on Multimedia (ISM), in Dec. 2022. |
|
Explaining the decisions of image/video classifiers. Presentation available in Slideshare. Delivered at the 1st Nice Workshop on Interpretability, Nice, France, in Nov. 2022. |
|
Learning Visual Explanations for DCNN-Based Image Classifiers Using an Attention Mechanism. Presentation available in Slideshare. Delivered at the ECCV 2022 Workshop on Vision with Biased or Scarce Data (VBSD), in Oct. 2022. |
|
Are All Combinations Equal? Combining Textual and Visual Features with Multiple Space Learning for Text-Based Video Retrieval. Presentation available in Slideshare. Delivered at the ECCV 2022 Workshop on AI for Creative Video Editing and Understanding (CVEU), in Oct. 2022. |
|
Summarizing videos using concentrated attention and considering the uniqueness and diversity of the video frames. Presentation available in Slideshare. Delivered at the ACM Int. Conf. on Multimedia Retrieval (ICMR’22), in June 2022. |
|
Combining Global and Local Attention with Positional Encoding for Video Summarization. Presentation available in Slideshare. Delivered at the IEEE Int. Symposium on Multimedia (ISM), in Dec. 2021. |
|
A Web Service for Video Smart-Cropping. Presentation available in Slideshare. Delivered at the IEEE Int. Symposium on Multimedia (ISM), in Dec. 2021. |
|
Combining Adversarial and Reinforcement Learning for Video Thumbnail Selection. Presentation available in Slideshare. Delivered at the ACM Int. Conf. on Multimedia Retrieval (ICMR), in Nov. 2021. |
|
Hard-negatives or Non-negatives? A hard-negative selection strategy for cross-modal retrieval using the improved marginal ranking loss. Presentation available in Slideshare. Delivered at the 2nd Int. Workshop on Video Retrieval Methods and Their Limits (ViRaL) @ Int. Conf. on Computer Vision (ICCV), in Oct. 2021. |
|
A Fast Smart-Cropping Method and Dataset for Video Retargeting. Presentation available in Slideshare. Delivered at the 28th IEEE Int. Conf. on Image Processing (ICIP), in Sept. 2021. |
|
Automatic and Semi-automatic Augmentation of Migration Related Semantic Concepts for Visual Media Retrieval. Presentation available in Slideshare. Delivered at the Workshop on Open Challenges in Online Social Networks (OASIS) @ the 32nd ACM Conference on Hypertext and Social Media (ACM HT'21), in Aug.-Sept. 2021. |
|
ObjectGraphs: Using Objects and a Graph Convolutional Network for the Bottom-up Recognition and Explanation of Events in Video. Presentation available in Slideshare. Delivered at the 2nd Int. Workshop on Large Scale Holistic Video Understanding (HVU) @ the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), in June 2021. |
|
Misinformation on the internet: Video and AI. Presentation available in Slideshare. Delivered at the Age of misinformation: an interdisciplinary outlook on fake news workshop/webinar, in Dec. 2020. |
|
Structured Pruning of LSTMs via Eigenanalysis and Geometric Median for Mobile Multimedia and Deep Learning Applications. Presentation available in Slideshare. Delivered at the 22nd IEEE Int. Symposium on Multimedia (ISM), Dec. 2020. |
|
Performance over Random: A robust evaluation protocol for video summarization methods. Presentation available in Slideshare. Delivered at ACM Multimedia 2020 (ACM MM), Seattle, WA, USA, Oct. 2020. |
|
Migration-Related Semantic Concepts for the Retrieval of Relevant Video Content. Presentation available in Slideshare. Delivered at INTAP 2020, in Oct. 2020. |
|
GAN-based video summarization. Presentation available in Slideshare. Delivered at AI4Media Workshop on GANs for Media Content Generation, in Oct. 2020. |
|
Video Summarization and Re-use Technologies and Tools: Automatic video summarization. Tutorial delivered at the IEEE Int. Conf. on Multimedia and Expo (ICME), 6-10 July 2020. Slides available in Slideshare. |
|
Fractional Step Discriminant Pruning: A Filter Pruning Framework for Deep Convolutional Neural Networks. Presentation available in Slideshare. Delivered at the 7th IEEE Int. Workshop on Mobile Multimedia Computing (MMC2020), IEEE Int. Conf. on Multimedia and Expo (ICME), London, UK, July 2020. |