Research Directions
The research activities and know-how of the lab revolve around:
- Video/image/multimedia understanding, search and organization: this research track focuses on the development of new methods for solving problems such as media annotation (with e.g. concept and event labels), video fragmentation and object detection, sentiment analysis, cross-modal search (i.e., free-text search within image/video collections), analysis of special types of media (e.g. lecture videos), summarization and re-purposing of videos and media collections.
- Artificial Intelligence (AI) – machine learning and deep learning: this research track focuses on the development of new deep learning architectures and other machine learning algorithms for addressing various problems, both in the video/image/multimedia understanding domain and beyond this. Research in this track includes, for example, learning to create more compact deep networks, and learning to explain the decisions of deep networks (explainable AI).
- Applications of media understanding and AI in various business sectors and for addressing major societal challenges. Examples include the News and New Media sectors (e.g. media adaptation and re-purposing; combatting disinformation); Cultural applications; Security and migration-related applications; Training and reskilling/upskilling the workforce; Healthcare and wellbeing (e.g. supporting people with intellectual disabilities); and other industrial applications.
- Development of training services for the research community as well as vocational training services, development of services in the domain of e-Government and technologies for Smart Cities, and coordination of activities for the implementation of innovative e-Services for governmental bodies, regional and national authorities, cultural and educational organizations.
Research Highlights
| Combining Adversarial and Reinforcement Learning for Video Thumbnail Selection. We developed a new method for unsupervised video thumbnail selection. The developed network architecture selects video thumbnails based on two criteria: the representativeness and the aesthetic quality of their visual content. Training relies on a combination of adversarial and reinforcement learning. The former is used to train a discriminator, whose goal is to distinguish the original from a reconstructed version of the video based on a small set of candidate thumbnails. The discriminator’s feedback is a measure of the representativeness of the selected thumbnails. This measure is combined with estimates about the aesthetic quality of the thumbnails (made using a SoA Fully Convolutional Network) to form a reward and train the thumbnail selector via reinforcement learning. Experiments on two datasets (OVP and Youtube) show the competitiveness of the proposed method against other SoA approaches. An ablation study with respect to the adopted thumbnail selection criteria documents the importance of considering the aesthetics, and the contribution of this information when used in combination with measures about the representativeness of the visual content. |
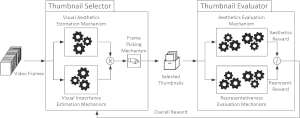
|
| ObjectGraphs: Using Objects and a Graph Convolutional Network for the Bottom-up Recognition and Explanation of Events in Video. ObjectGraphs is a novel bottom-up video event recognition and explanation approach. It utilizes a rich frame representation and the relations between objects within each frame. Specifically, following the application of an object detector (OD) on the frames, graphs are used to model the object relations and a graph convolutional network (GCN) is utilized to perform reasoning on the graphs. The resulting object-based frame-level features are then forwarded to a long short-term memory (LSTM) network for video event recognition. Moreover, the weighted in-degrees (WiDs) derived from the graph’s adjacency matrix at frame level are used for identifying the objects that were considered most (or least) salient for event recognition and contributed the most (or least) to the final event recognition decision, thus providing an explanation for the latter. Experimental evaluation shows that the proposed ObjectGraphs method achieves state-ofthe-art performance on the publicly available FCVID and YLI-MED datasets. |
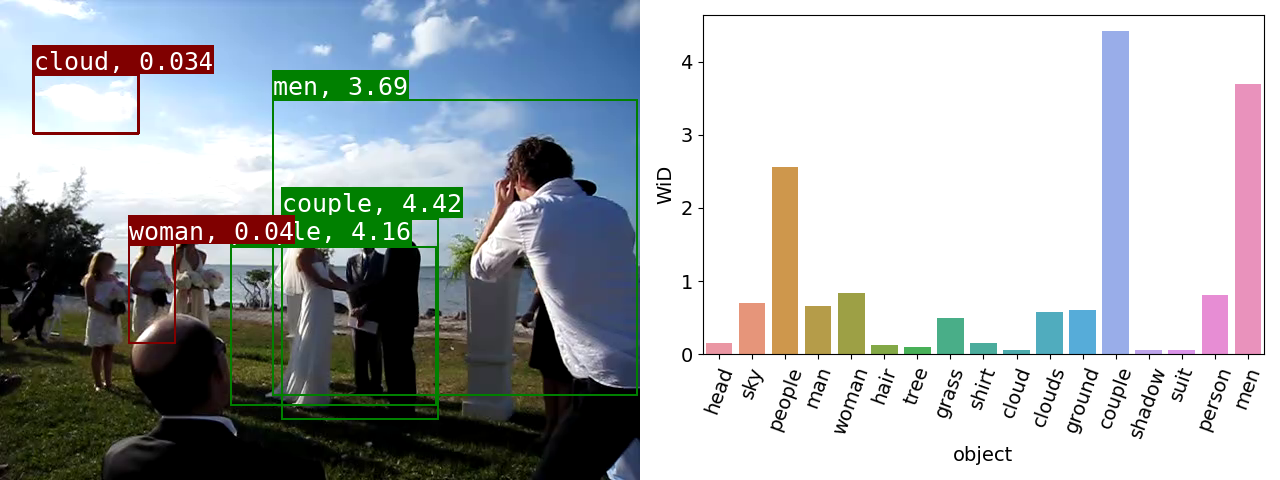
|
| AC-SUM-GAN: Connecting Actor-Critic and Generative Adversarial Networks for Unsupervised Video Summarization. The proposed architecture embeds an Actor-Critic model into a Generative Adversarial Network and formulates the selection of important video fragments (that will be used to form the summary) as a sequence generation task. The Actor and the Critic take part in a game that incrementally leads to the selection of the video key-fragments, and their choices at each step of the game result in a set of rewards from the Discriminator. The designed training workflow allows the Actor and Critic to discover a space of actions and automatically learn a policy for key-fragment selection. Moreover, the introduced criterion for choosing the best model after the training ends, enables the automatic selection of proper values for parameters of the training process that are not learned from the data (such as the regularization factor σ). Experimental evaluation on two benchmark datasets (SumMe and TVSum) demonstrates that the proposed AC-SUM-GAN model performs consistently well and gives SoA results in comparison to unsupervised methods, that are also competitive with respect to supervised methods. |
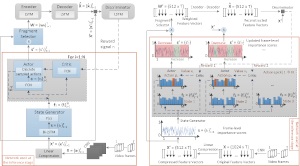
|
| Structured Pruning of LSTMs via Eigenanalysis and Geometric Median for Mobile Multimedia and Deep Learning Applications. A novel structured pruning approach for learning efficient long short-term memory (LSTM) network architectures is proposed. More specifically, the eigenvalues of the covariance matrix associated with the responses of each LSTM layer are computed and utilized to quantify the layers’ redundancy and automatically obtain an individual pruning rate for each layer. Subsequently, a Geometric Median based (GM-based) criterion is used to identify and prune in a structured way the most redundant LSTM units, realizing the pruning rates derived in the previous step. The experimental evaluation on the Penn Treebank text corpus and the large-scale YouTube-8M audio-video dataset for the tasks of word-level prediction and visual concept detection, respectively, shows the efficacy of the proposed approach. |
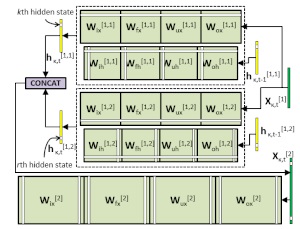
|
| Performance over Random: A Robust Evaluation Protocol for Video Summarization Methods. We propose a new evaluation approach for video summarization algorithms. We start by studying the currently established evaluation protocol, which quantifies the agreement between the user-defined and the automatically-created summaries using F-Score. We show that the F-Score results typically reported in papers, using a few data splits, are not always congruent with the performance obtained in a larger-scale experiment, and that the F-Score cannot be used for comparing algorithms evaluated on different splits. To mitigate these shortcomings we propose an evaluation protocol that makes estimates about the difficulty of each used data split and utilizes this information during the evaluation process. Experiments involving different evaluation settings demonstrate the increased representativeness of performance results when using the proposed evaluation approach, and the increased reliability of comparisons when the examined methods have been evaluated on different data splits. |
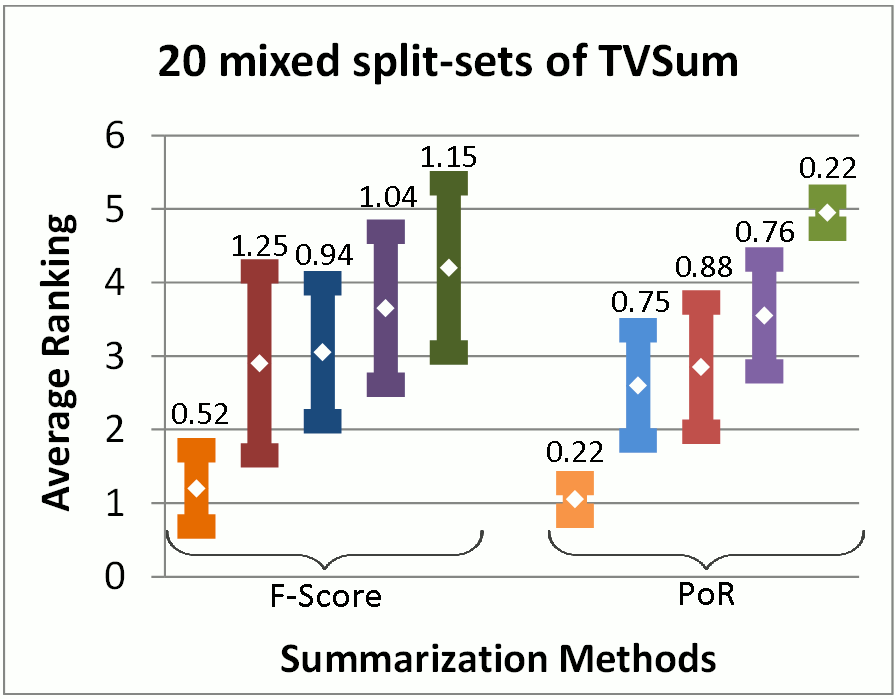
|
| Attention Mechanisms, Signal Encodings and Fusion Strategies for Improved Ad-hoc Video Search with Dual Encoding Networks. In this paper, the problem of unlabeled video retrieval using textual queries is addressed. We present an extended dual encoding network which makes use of more than one encodings of the visual and textual content, as well as two different attention mechanisms. The latter serve the purpose of highlighting temporal locations in every modality that can contribute more to effective retrieval. The different encodings of the visual and textual inputs, along with early/late fusion strategies, are examined for further improving performance. Experimental evaluations and comparisons with state-of-the-art methods document the merit of the proposed network. |
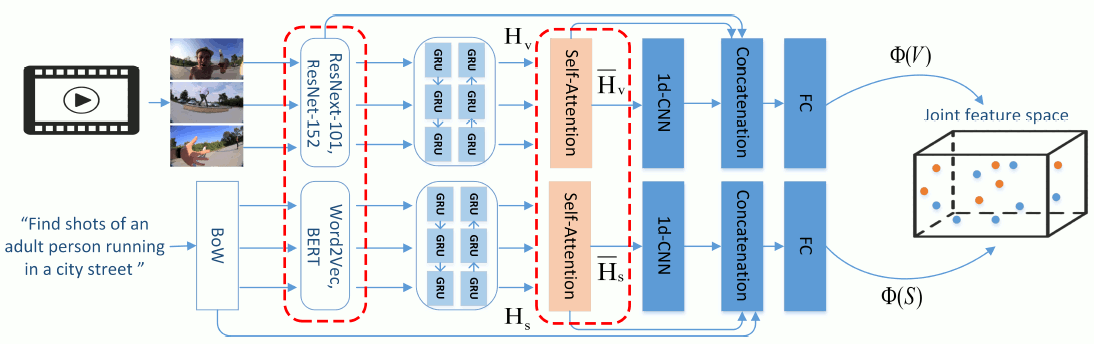
|
| Fractional Step Discriminant Pruning: A Filter Pruning Framework for Deep Convolutional Neural Networks. In this paper, a novel pruning framework is introduced to compress noisy or less discriminant filters in small fractional steps, in deep convolutional networks. The proposed framework utilizes a class-separability criterion that can exploit effectively the labeling information in annotated training sets. Additionally, an asymptotic schedule for the pruning rate and scaling factor is adopted so that the selected filters’ weights collapse gradually to zero, providing improved robustness. Experimental results on the CIFAR-10, Google speech commands (GSC) and ImageNet32 (a downsampled version of ILSVRC-2012) show the efficacy of the proposed approach. |
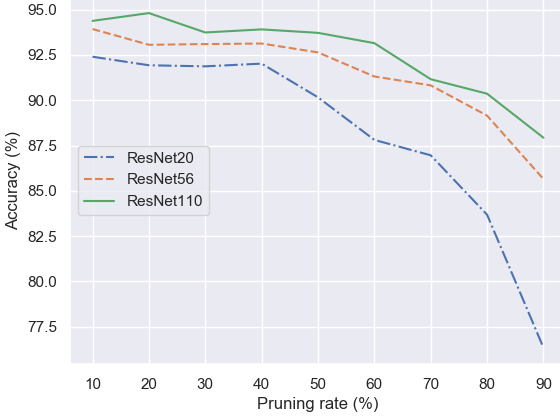
|